
C言語やC++系のプログラミングを学び始めると
文字データを入れる変数はchar型だと習うが、
半角文字を1バイト、全角文字を2バイトという
特殊な考え方は「マルチバイト文字」と呼ばれ、
日本語用のShift_JISなど特定の言語だけを想定した設計になっている。
そうなると外国語環境では文字化けしてしまうため、
世界標準の統一規格であるUnicodeで管理する方が望ましい。
Unicodeならどの環境であっても日本語は日本語として表示される。
Unicodeは1文字を表す情報量を増やしたワイド文字という仕様の一種で、
プログラム上ではchar型からwchar_t型に変わる。
今回、ウゴツールをUnicodeに対応するにあたって
必要になった知識を備忘録としてまとめておく。
(この情報が最初からあれば作業時間は10分の1で済んだ)
プロジェクトの文字セットを変更
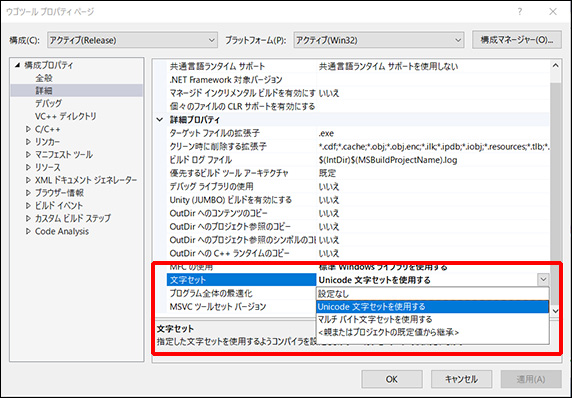
プロジェクトのプロパティ内「詳細」にある
「文字セット」を「Unicode」に切り替える。
これによって文字列を扱うWindowsAPIは
すべて自動的にUnicodeを使うものに切り替わる。
これはUNICODEマクロが定義されているかどうかで
同じSendMessage関数でも
SendMessageWとSendMessageAのどちらを呼び出すかが変わるよう
条件コンパイルが指定されているためだ。
切り替えた直後はあちこちでビルドエラーが起きるため、
それぞれをワイド文字(Unicode)版に置き換えていく。
文字列の変換
■メッセージボックス■
MessageBox ( hwnd, "おはよう", "挨拶", MB_OK ) ;
↓ ↓ ↓
MessageBox ( hwnd, L"おはよう", L"挨拶", MB_OK ) ;
ダブルクォーテーションで囲んで直接文字列を記述している箇所は
「L」を頭に付けることでワイド文字として扱われるようになる。
■char型 ⇒ ワイド文字の変換■
char mbText [ ] = "おはよう" ;
wchar_t uText [ sizeof ( mbText ) ] ;
MultiByteToWideChar ( CP_ACP, 0, mbText, -1, uText, sizeof ( uText ) / sizeof ( wchar_t ) ) ;
char型として作られた文字列は
MultiByteToWideChar関数を使うことで
ワイド文字に変換することができる。
■ワイド文字 ⇒ char型の変換■
wchar_t uText [ ] = L"ありがとう" ;
char mbText [ sizeof ( uText ) ] ; //半角文字があると余りが発生する
WideCharToMultiByte ( CP_ACP, 0, uText, -1, mbText, sizeof ( mbText ) , NULL, NULL ) ;
逆にWindowsAPIなどから受け取ったワイド文字を
通常のchar型として扱いたい場合は
WideCharToMultiByte関数で変換できる。
これで互いの文字セットが行き来できるため
理屈としては上記の方法だけでもすべて対応できるのだが、
うまく関数を置き換えれば
ワイド文字のまま操作できるので変換の手間が省ける。
標準ライブラリ関数の置き換え
■文字列のコピー■
char src [ ] = "おはよう" ;
char dest [ 100 ] ;
strcpy_s ( dest, sizeof ( dest ) , src ) ;
↓ ↓ ↓
wchar_t src [ ] = L"おはよう" ;
wchar_t dest [ 100 ] ;
wcscpy_s ( dest, sizeof ( dest ) / sizeof ( wchar_t ), src ) ;
※第2引数はバイト数ではなく文字数であることに注意
文字数指定のstrncpy_sとwcsncpy_sも同様。
■文字数を測る■
char mbText [ ] = "おはよう" ;
int len;
len = strlen ( mbText ) ;
↓ ↓ ↓
wchar_t uText [ ] = L"おはよう" ;
int len;
len = wcslen ( uText ) ;
■文字列を連結する■
char mbText [ 100 ] = "おはよう" ;
strcat_s ( mbText, sizeof ( mbText ), "ございます" ) ;
↓ ↓ ↓
wchar_t uText [ 100 ] = L"おはよう" ;
wcscat_s ( uText, sizeof ( uText ) / sizeof ( wchar_t ), L"ございます" ) ;
※第2引数はバイト数ではなく文字数
■文字列を比較する■
char mbText1 [ 100 ] = "おはよう" ;
char mbText2 [ 100 ] = "こんにちは" ;
if ( strcmp ( mbText1, mbText2 ) == 0 )
{}
↓ ↓ ↓
wchar_t uText1 [ 100 ] = L"おはよう" ;
wchar_t uText2 [ 100 ] = L"こんにちは" ;
if ( wcscmp ( uText1, uText2 ) == 0 )
{}
■文字列を成形する■
char mbText [ 100 ] ;
int no = 13;
sprintf_s ( mbText, sizeof ( mbText ) , "テスト%d回目", no ) ;
↓ ↓ ↓
wchar_t uText [ 100 ] ;
int no = 13;
swprintf_s ( uText, sizeof ( uText ) / sizeof ( wchar_t ) , L"テスト%d回目", no);
※第2引数はバイト数ではなく文字数
■テキストファイルに書き込む■
FILE* fp ;
fopen_s ( &fp, "mbFile.txt", "w" ) ;
int no = 13 ;
char mbText [ ] = "おはよう" ;
fprintf_s ( fp, "データ %d , %s", no, mbText ) ;
fclose ( fp ) ;
↓ ↓ ↓
FILE* fp ;
_wfopen_s ( &fp, L"uFile.txt", L"w, ccs = UNICODE" ) ;
int no = 13 ;
wchar_t uText [ ] = L"おはよう" ;
fwprintf_s ( fp, L"データ %d , %s", no, uText) ;
fclose ( fp ) ;
■テキストファイルから読み込む■
FILE* fp ;
int no ;
char mbText [ 100 ] ;
fopen_s ( &fp, "mbFile.txt", "r" ) ;
fscanf_s ( fp, "%d,%s", &no, mbText, sizeof ( mbText ) ) ;
fclose ( fp ) ;
↓ ↓ ↓
FILE* fp ;
int no ;
wchar_t uText [ 100 ] ;
_wfopen_s ( &fp, L"uFile.txt", L"r, ccs = UNICODE" ) ;
fwscanf_s ( fp, L"%d,%s", &no, uText, sizeof ( uText ) / sizeof ( wchar_t ) ) ;
fclose ( fp ) ;
※文字列変数のサイズはバイト数ではなく文字数
まとめ
TCHAR型やTEXT()マクロなどを使えば
マルチバイト文字にもワイド文字にも対応した記述もできるが、
そもそもUnicode対応したプログラムを
元に戻す必要性がほとんどないので、
可能なら最初からUnicode前提ですべて記述した方がいいだろう。
文字セットの違いに悩むプログラマーにとって
この記事が少しでも役立つことを願う。