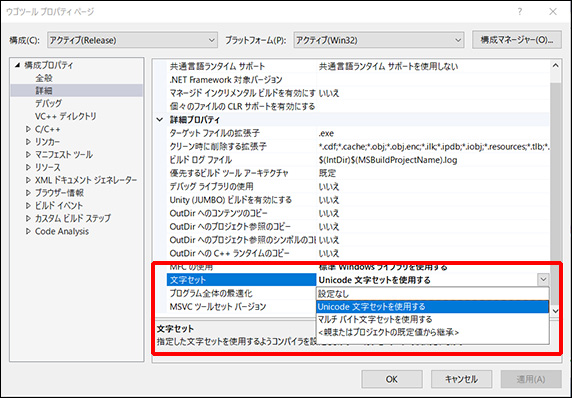
ゲームにはさまざまな武器が登場するが、
銃弾は直線的な軌道として処理することが多い。
現実には弾丸も重力の影響を受けて放物線を描くのだが、
一般的なイメージとして銃の弾が徐々に落下するという印象が薄いし、
そこまで計算して敵に狙いをつけるのは
ゲームとしての面白みに欠けるからだ。
しかし、戦車砲やグレネードランチャー、弓矢などは
山なりに飛んでいく印象が強いため、
重力を無視して飛ばしてしまうと不自然に見えてしまう。
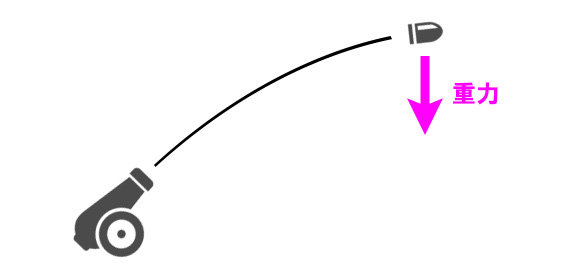
そこで発射された弾は、重力によって
徐々に下に落ちていくように処理する。
移動量は2つに分解して処理する
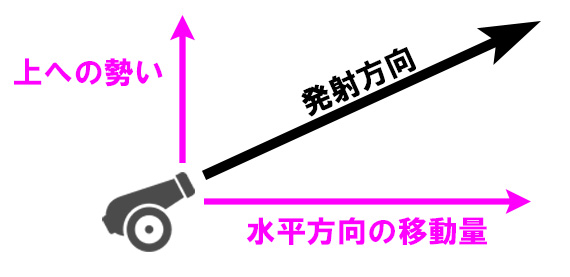
プログラム的には垂直方向の移動処理と
水平方向の移動処理を別々に管理した方が楽なので、
発射時の角度をもとに三角関数を使って
移動量を水平方向と垂直方向に分解する。
このうち水平方向の移動量は減衰せず、
毎回同じ分だけ弾の座標に足し込んでいく。
空気抵抗を考えても誰も得しないので普通は無視する。
垂直方向の移動量は徐々に減少していって
いずれマイナス値になるのだ。
つまり、弾は下降していくことになる。
さて、主人公が発射する武器はプレイヤーが操作をするので
発射時の向きに合わせて弾を飛ばすだけでいい。
弾の着弾位置から発射方向を修正する作業がゲーム性につながる。
問題は敵が弾を発射する場合だ。
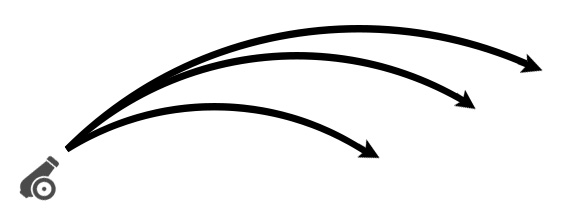
敵はプレイヤーが操作するわけではないので
主人公にうまく当たるように弾を撃たせる必要があるが、
発射する角度によって弾の飛距離が変わるので、
目標までの距離に応じて角度を求める必要がある。
しかし重力によって垂直方向の移動量が変化するため
どんな角度で撃ち出せば
ちょうど目標地点に落ちるかという計算はなかなか難しい。
今回はこの計算方法を紹介してみる。
着弾するまでの滞空時間を求める
まず手順としては、弾が地面に着くまでの時間を求める。
そのために垂直方向の移動量を抜き出す必要があるが、
これには三角関数を使う。

直角三角形の角度と斜辺の長さがわかれば
コサインを使って底辺の長さとを求めることができる。
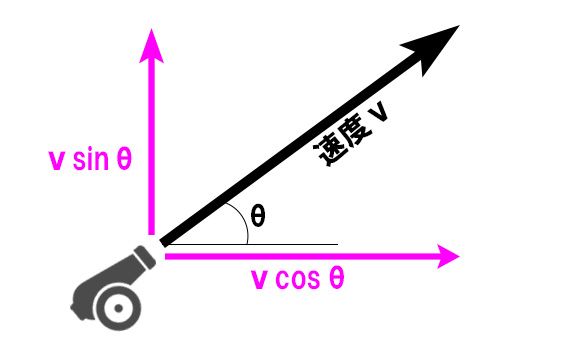
つまり、角度θの方向にvの速度で発射された弾は
水平方向にv×コサインθ 、
垂直方向にv×サインθ の力で撃ち出された考えられる。
次に高校物理で出てくる等加速度運動の公式を使う。
上方向をプラスとした場合、
初速度 、重力加速度
に対する時間
のときの高さ
は
となるので、この に
先ほどの垂直方向の発射速度 を当てはめると
になる。
弾が地面に着くということは が
になるときなので
になるときの の値を求めればいいわけだ。
この式を並び替えると
となり、2次方程式の
と同じ形になる。
が
、
が
、
が
、
が
ということだ。
2次方程式なら中学数学で習う
解の公式が使える。
この式にそれぞれを当てはめると
となるが、これを整理していくと
と、かなりシンプルにすることができて
±の関係で2つの解が出る。
つまり弾の高さが0になる時間は と
ということだ。
このうち時間 というのは発射の瞬間を表しているので、
発射角度 における着弾までの時間は
となる。
サイン値が最大となるのは90度なので
が90に近づくほど
の値も大きくなる。
要するに、上向きに撃つほど
滞空時間が長くなるという納得の結果になっている。
滞空時間をもとに飛距離を求める
角度θの方向にvの速度で発射された弾は
水平方向にはv×コサインθ だけ進む。
こちらは重力には左右されないので速度は変化しない。
等速運動の移動量は等加速度運動の公式である
の加速度 が
になっている状態なので、
となるが、この の部分に
を当てはめれば
となり、弾が水平方向に対して
どのぐらい移動するかを求めることができる。
この式の に先ほど求めた滞空時間
を当てはめれば
となり、少し式を整理すると
という形になる。
三角関数の加法定理に
があるが、 の場合に置き換えてみると
となり、
とすることができる。
ということは先ほど作った式、
の「 」の部分を
そっくり「 」に置き換えることができるので、
という式になる。
これが角度 で弾を発射したときの飛距離だ。
放物線で移動する物体は高さと推進力のバランスから
45度で発射されたときが一番よく飛ぶわけだが、
上記の に45が入ると、サイン値の最大である
90度が使われるようになっているのがわかる。
また、発射速度 が大きくなれば飛距離
が増え、
重力加速度 が大きくなれば飛距離
が小さくなることからも
計算として正しいことが感覚的にわかるだろう。
45度で発射したときの飛距離より遠くには
どう撃っても絶対に弾は届かないので、
敵のAI処理ではまず上記の式の に45を代入して射程距離
を求め、
目標がそれより近いときだけ攻撃するようにすべきだ。
飛距離から逆算して発射角度を割り出す
さて、目標が射程範囲内にいる場合は
適切な発射角度を求めて攻撃する必要があるため、
先ほどたどり着いたこの式を少し変形して
左辺にサイン値がくるようにする。
これを見ると がサイン値と等しいことがわかる。
角度からサイン値を求める場合はサイン関数を使うが、
サイン値から角度を求める場合は
サインの逆関数であるアークサインを使う。
ようやくたどり着いた。
これが目標との距離 、重力加速度
、発射速度
をもとに
適切な発射角度を割り出す計算式となる。
ここまでたどり着くのに
- 三角関数
- 等加速度運動
- 加法定理
- 解の公式
- 逆三角関数
といった数学知識を活用する必要があり、
中学高校での勉強が大切なことを実感する。
実践での工夫
もともとこの処理は18年ほど前に作った
自作ゲーム「ネイビーミッション」で
艦砲射撃をしてくる敵の攻撃AIとして必要だったのだ。
当時はかなり四苦八苦して上記の結論に達したのを覚えている。
さらに後半のステージで登場する強めの敵では
途中に出てきた発射角度から滞空時間を求める式
を使って、敵弾が飛んでいる間に
自機が進むであろう位置を先読みして
未来の座標に向けて発射するようにもした。
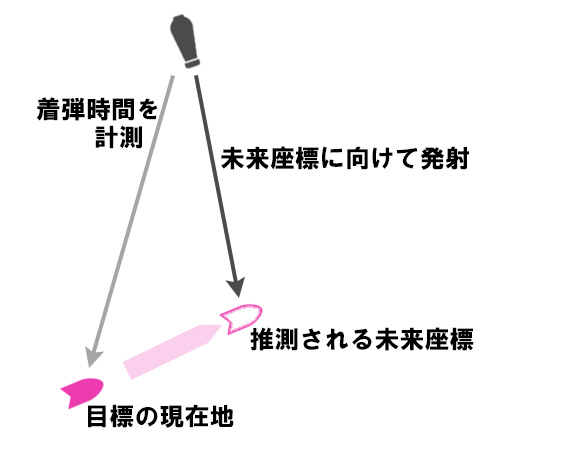
いわゆる偏差(へんさ)射撃というやつだが、これによって
「とりあえず移動していれば当たらない」という序盤の敵に対して
「攻撃してきたら移動方向を変えないと喰らう」という強敵が作れた。
開発中にややこしい計算をした感触だけは覚えていたので
当時の資料を掘り起こしてきちんと記録にまとめてみた。
(数式をブログ上で表現するTeX記法の練習にもなった)
同じような計算が必要になるプログラマーに
少しでも役立てばと思う。